返回
返回


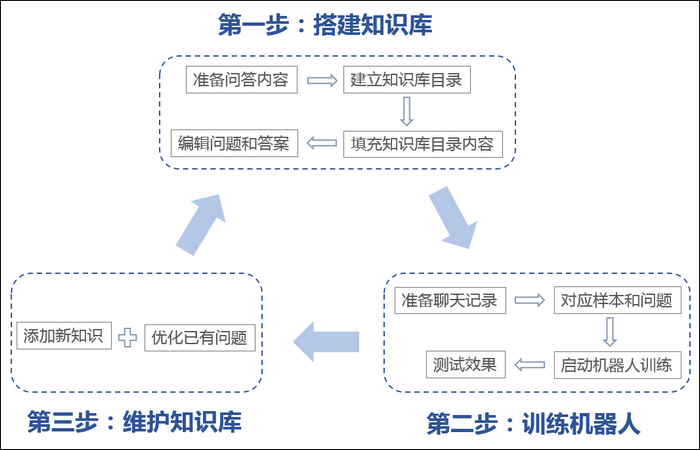
维护知识库
一、为什么需要维护知识库
一个好的知识库必定是不断迭代、长期维护的,要想维护好识库需要先了解两个概念,覆盖率和准确率。
覆盖率:即在企业所有问答内容中,知识库中问答覆盖的比例。提高覆盖率可以让机器人解决更多问题。而提高覆盖率的方法,一方面是及时添加新知识,另一方面是处理【未识别问题】,针对未识别的问题进行训练或新增。
准确率:即机器人回复准确的概率。要想提高准确率,需要对回复不准的问题进行有针对性的优化,并对知识库的问答不断更新和迭代。
二、提高覆盖率(让回复的问答越来越多)
1. 及时添加新知识
若新活动上线或业务调整,需要增加或调整对应的问答内容,样本可人工编写一部分,后续再逐渐补充。
2. 处理【未识别问题】
顾名思义,【未识别问题】是为机器人无法识别的问题。
分为两种情况,知识库已有对应的问题或还未覆盖。如已有对应的问题就添加上去,如还没有则新增问题。通过这种方式可覆盖更多业务场景,提高机器人识别率。
处理方法:
a)在处理未识别问题前,需要对聚类的相似问题进行人工审核,删除含义不符的提问样本,再进行添加新问题或者学习到已有问题。
b)将未识别问题列表中,知识库未覆盖的问题添加为新问题。
c)将未识别问题列表中,知识库已覆盖,但机器人识别错误的问题学习到已有问题。
d)完成以上后,一键启动训练学习。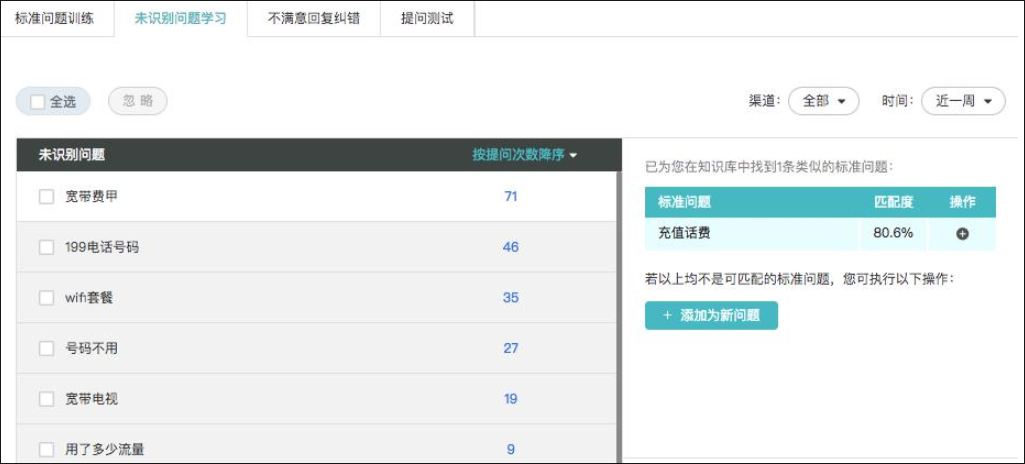
三、提高准确率(让回复的问答越来越精准)
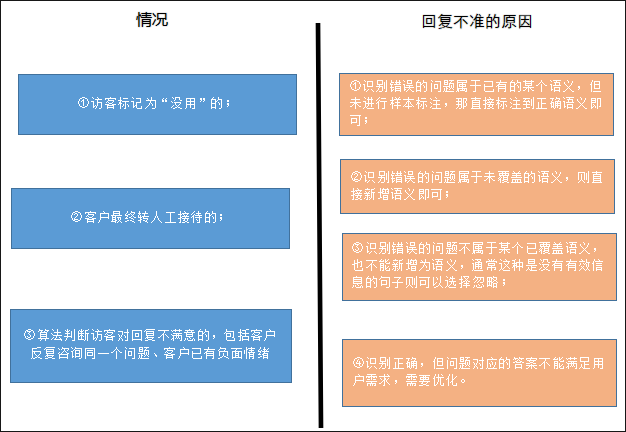
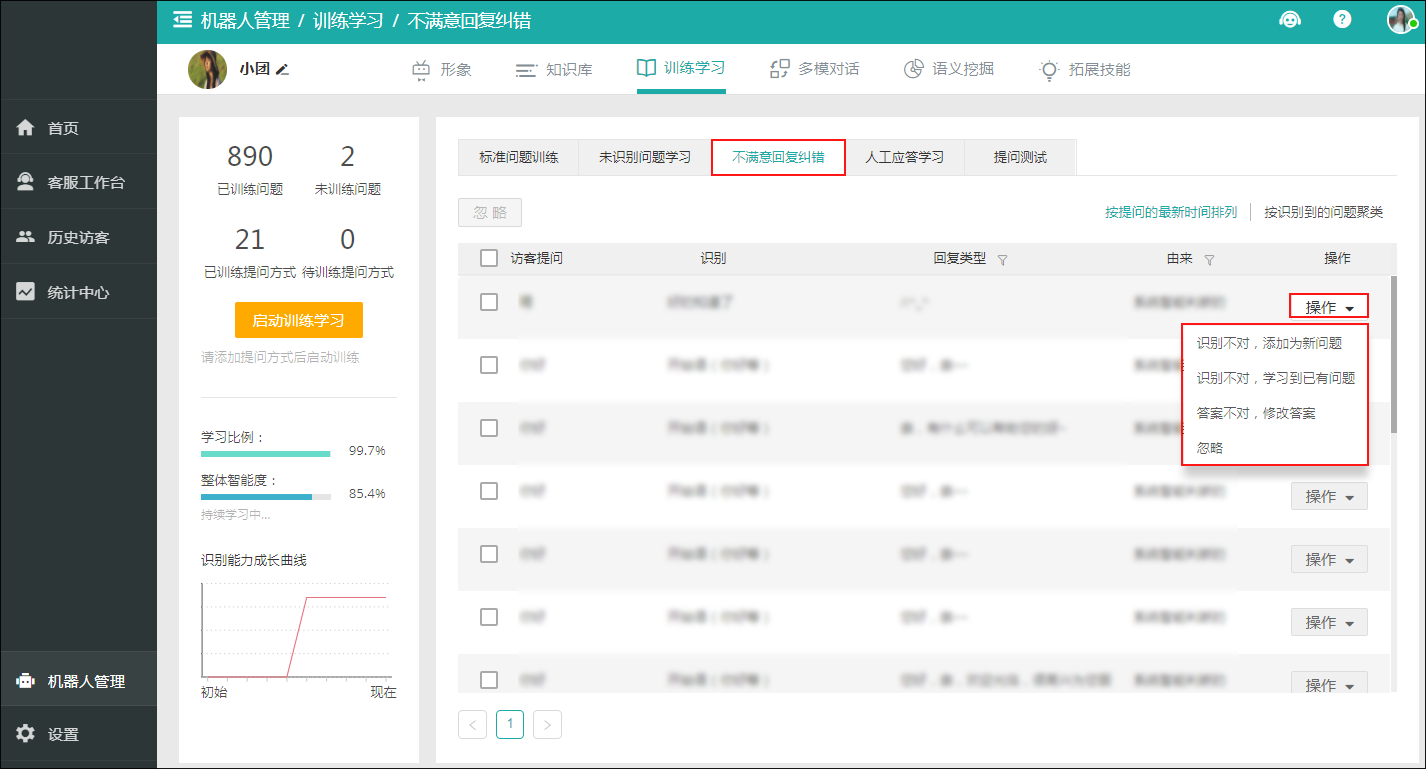
1. 优化已识别问题
2. 优化推荐问题
推荐问题是在客户问题不够明确,或回复准确率不够高的情况出现。如客户咨询“快递”,机器人回复“您是否想咨询以下问题?1.发什么快递?2.快递到哪儿了。”
在进行纠错时,若推荐问题中包含正确选项,把问题标注到正确选项中。若推荐问题中不包含正确选项,同已识别问题维护。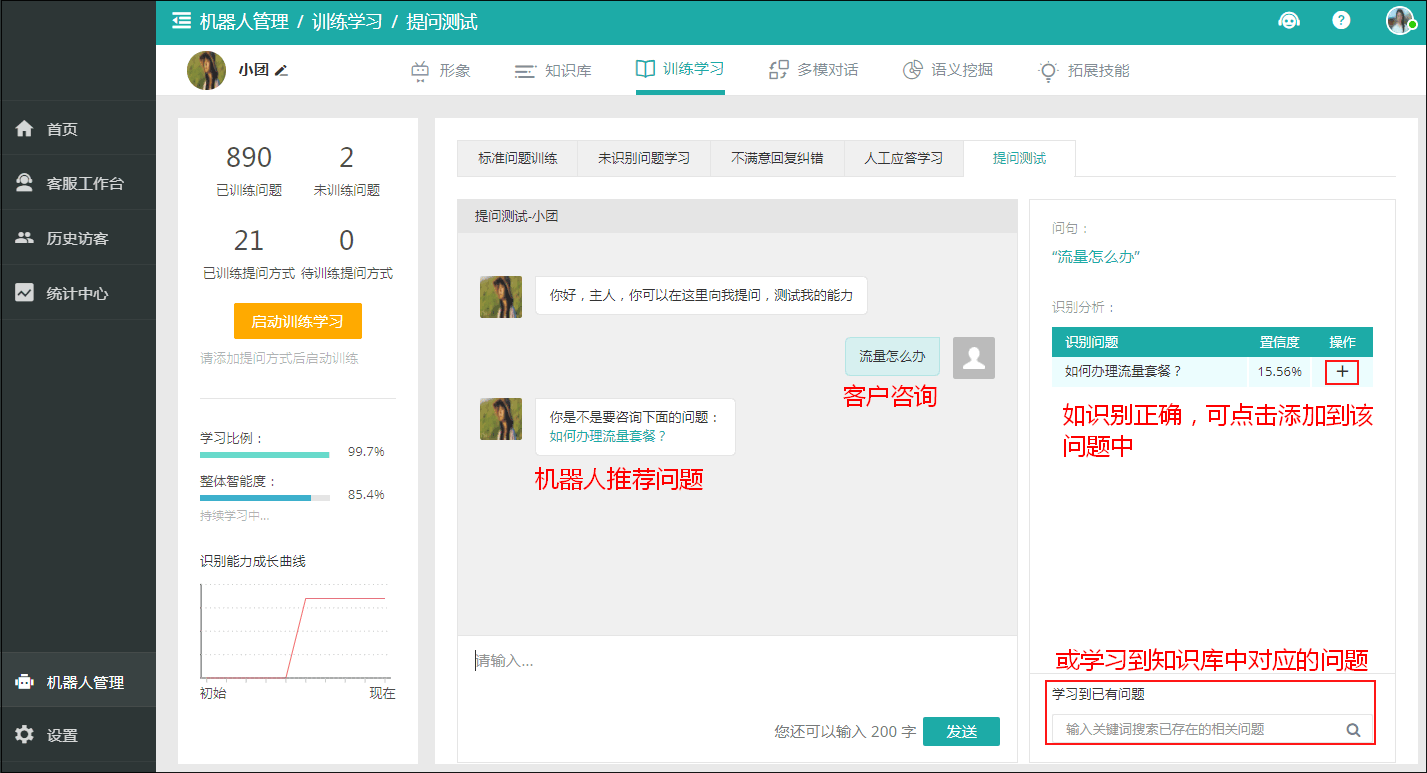
3. 对原有问题进行合理的拆分和合并
在前提建立知识库中,或许因为业务了解深度不够,或对客户咨询环境的了解有限,或许将同一个答案设置了多个问题、多个答案的问题设置成一个问题。那就需要进行合理的拆分和合并处理,加大回复的准确率,同时降低知识库维护的成本。
如“申请退换货流程”,如退货和换货的流程不同,则可以拆分为“申请退货流程”“申请换货流程”。
如“是否有赠品”“赠品是什么”这2个问题答案相同的话,则可以合并为“赠品是什么”。
4. 优化badcase
有时候我们会遇到一些识别或回复错误的问题(即badcase),对于这部分问题,则需要找到产生的原因,再有针对性地进行优化。
产生途径:
a)模型识别错误:训练样本数量少,可适当多添加训练样本,原则上样本数量越多越好
b)标注错误:纠正错误的样本
c)答案配置错误或不完整:定期优化答案,尤其是活动类业务相关的问题
常见问题
1. 搭建知识库时,如果没有问答内容怎么办?
a)如没有问答内容,只有聊天记录,可导入到【人工问答学习】,机器人自动从聊天记录里提取问题和答案,无需人工再进行整理。
b) 如既无问答内容,也无聊天记录的话,可暂时不使用机器人,让人工客服接待一段时间,知识库会自动积累机器人无法识别的问题,再统一进行处理即可。
2. 训练机器人时,如果没有样本怎么办?
样本建议从历史聊天记录中提取出来,如果暂时没有聊天记录,可以先为每个问题编写3-10个样本,待使用一段时间积累了聊天记录后,再对样本进行补充。
以上就是知识库运营的全部内容。除了概念,更重要的是要结合实践去理解,你都学会了吗?